[Elastic Cloud] Elastic Cloud로 이관 작업
Contents
개요
-
filebeat,logstash는 데이터 소스가 있는 시스템에 설치하고,Elasticsearch,Kinaba는Elastic Cloud로 세팅하여 사용한다. -
엘라스틱서치 운영 모니터링 까지 Elastic Cloud 에서 모두 지원하기 때문에 따로 구성하지 않아도 된다.
Elastic Cloud 구조
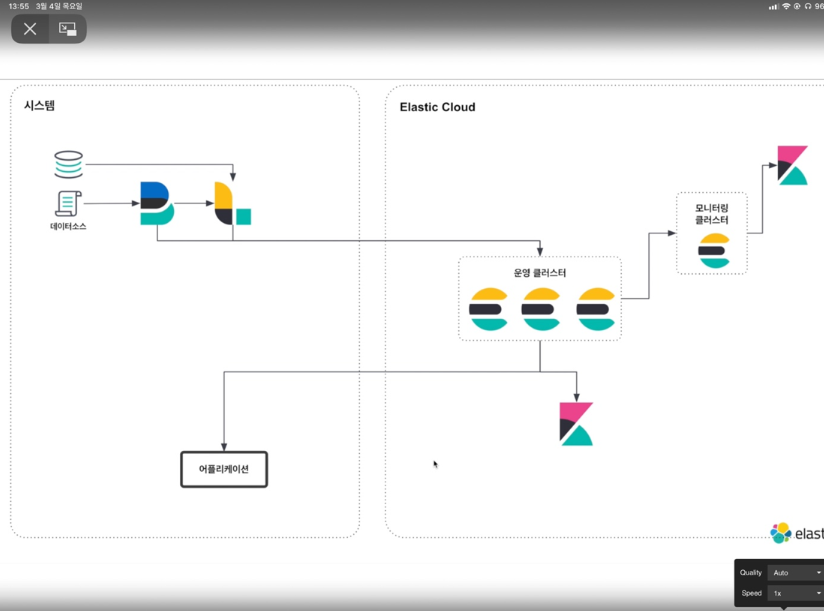
작업 목표
- On-promise로 구성되어 있는 검색어 키워드를 Elastic Cloud 환경으로 이관한다.
- 추후에 맵으로 시각화 할 수 있도록 기존 데이터에 location(latitude, longitude)를 추가한다.
현재 시스템 구성
- 현재 구성되어 있는 검색어 키워드 인덱스 명 →
wini_srch_kwrd_hist-yyyymm - ES_MASTER 서버에서 로그스태시가 매일 09:00 마다 키워드 테이블을 조회하여 엘라스틱서치에 저장시키고 있다.
- 현재 로그스태시 및 구성 문서 : 기간별 키워드 검색 추가를 위한 선행 작업(링크)
작업 진행 내용
1. Raw 데이터 검색 쿼리 - 전일 키워드 히스토리를 가져오는 SQL
2. ES 템플릿을 등록한다
-
v_countrycd의 경우 사실 keyword 필드는 필요없다. (현재 반영되어 있는게v_countrcyd.keyword필드를 바라보고 있어서 따로 수정은 못함) -
location은 lat, lon 의 Object 형태의 goe_point로 설정한다.
-
template 생성 JSON
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71PUT _template/keyword_template { "index_patterns": ["kwrd_hist-*"], "settings": { "index" : { "analysis" : { "filter" : { "english_stop" : { "type" : "stop", "stopwords" : "_english_" }, "filter_shingle" : { "max_shingle_size" : "3", "token_separator" : " ", "output_unigrams" : true, "type" : "shingle" } }, "normalizer": { "default_normalizer": { "type" : "custom", "filter" : ["lowercase", "asciifolding"] } }, "analyzer" : { "default_analyzer" : { "type" : "custom", "tokenizer" : "standard", "filter" : ["lowercase", "filter_shingle", "asciifolding"] } } } } }, "mappings": { "properties": { "seq" : { "type" : "long" }, "v_countrycd" : { "type" : "keyword", "normalizer": "default_normalizer", "fields": { "keyword" : { "type" : "keyword", "normalizer": "default_normalizer" } } }, "v_keyword" : { "type" : "text", "analyzer" : "default_analyzer", "search_analyzer": "default_analyzer", "fields": { "keyword" : { "type" : "keyword", "normalizer": "default_normalizer" } } }, "v_usercd" : { "type" : "keyword", "normalizer": "default_normalizer" }, "v_userid" : { "type" : "keyword", "normalizer": "default_normalizer" }, "location" : { "type" : "geo_point" }, "reg_dtm" : { "type" : "date" } } } }
iso_alpha2 데이터를 가지고 lat, lon 정보를 세팅하는 dictionary 파일을 생성한다.
- 데이터 소스에서 국가코드는 2자리로만 수집하고 있다.(V_COUNTRYCD) 이 국가코드로 특정 위치를 알아내기 위해 국가코드를 키로하고 값으로 lat, lon 정보를 Object로 갖는 사전을 구성해야 한다.
- JSON은 더블 쿼테이션이나 형식이 복잡해지므로 간결하게 yml로 구성하였다.
|
|
4. 데이터를 가공하여 Elastic Cloud로 전송하도록 로그스태시를 설정한다.
최초 데이터 ~ 어제 데이터까지 한 번만 인입하는 로그 스태시 설정
|
|
filter > translate plugin
|
|
- v_countrycd 값을 가지고 country_dic.yml 데이터를 참고하여 latitude값과 longitude 값을 가져와mapdata라는 임시 필드에 저장시킨다.
- fallback 에는 매핑되지 못했을 경우 nill 값으로 리턴한다.
filter > mutate
|
|
- 사전데이터에 존재하는 데이터의 경우 location 오브젝트의 lat 값에 latitude를 lon 값에 longitude 값을 저장한다.
- 임시 필드 mapdata는 삭제한다.
- 필드 데이터 타입을 float로 변경해준다.
output
|
|
- output에는 Elastic Cloud 정보를 적어준다.
- cloud_id
- cloud_auth
- on-promise 에서는 host를 적었는데 cloud의 경우는 cloud id와 인증정보만 추가하면 된다.
- cloud_auth에서
: 형식이므로 password를 적지 않도록 keystore를 생성해서 처리하는 방식을 검색해보았지만 잘 안나와서 기본 예제에 따름…
5. 로그스태시 실행
매일 오전 9시마다 데이터 수집하도록 logstash 설정 추가
스케쥴링 용 logstash Config 파일 추가
|
|
pipeline.yml 수정
- 이전 on-promise의 경우 -f 옵션을 주어 하나의 config 파일을 실행하였는데, 당분간은 on-promise 와cloud에 각각 데이터를 쌓아야 하 기 때문에 pipeline.yml을 이용하여 로그스태시를 실행 시키도록 한다.
데이터 실행 쉘 스크립트 수정
- f 옵션을 제거하고 pipelines.yml을 기준으로 로그스태시를 실행 시킬 수 있도록 실행 옵션을 추가한다.
|
|
적재 데이터 확인
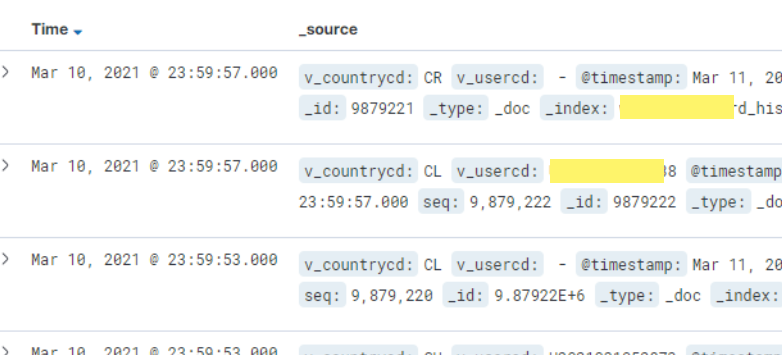
키바나에서 어제까지의 데이터가 들어와 있음 성공^ᄋ^
Alias 등록을 위한 스크립트 설정
- 검색 이력 인덱스는 “인덱스명-yyyyMMdd” 형태로 관리되고 있다.
- 별칭으로 전체 기간의 인덱스를 조회할 수 있도록 설정해야한다. 00시마다 크론탭에 의해 월이 넘어갔을때 신규인덱스에 별칭을 추가하도록 한다.
- 이전에 기록했던 설정 정보 : ALIAS 등록 스크립트 이전 스크립트에 elastic cloud 정보를 추가하도록 한다.
1. alias API 사용 권한을 갖는 API 키 발행
Kibana > Management > Dev Tools 에서 API Key를 추가한다.
- index는 alias에 등록될 인덱스 패턴과 별칭명도 추가해주어야 하는 것같다.
- privileges는 manage 로 설정한다.
|
|
Kiabana > Stack Management > API Keys
키가 추가가 잘되었는지 확인

2. 크론스크립트에 Cloud로 API를 요청하는 로직을 추가
|
|