[Elasticsearch 검색 엔진 구축 강의] Elasticsearch 개념 및 용어정리 - Inverted Index, Segment
Elasticsearch 검색 엔진 구축 강의 정리

Contents
1. Inverted Index
전통적인 데이터베이스는 필드당 하나의 값을 저장하기 때문에 전체 텍스트 검색에는 적합하지 않다. 즉, 다중 값을 색인화 할 수 있어야 하는데 Elasticsearch에서는 Inverted 인덱스 형태의 인덱싱을 통해 Full-Text 검색이 가능하다. 모든 문서에서 발생하는 모든 고유 값 또는 용어의 정렬된 목록을 포함하며 각 용어에 대해 이를 포함하는 모든 문서 목록을 표시한다.
Full-Text Search는 요청한 모든 단어를 문서 또는 데이터베이스에서 모든 단어와 비교하는 포괄적인 검색 방법이다. 전체 텍스트 쿼리에는 간단한 단어와 구 또는 여러 형식의 단어나 구가 포함될 수 있으며 텍스트 쿼리는 일치 항목이 하나 이상 있는 문서를 모두 반환한다.
Inverted Index
|
|
- Inverted Index 는 단어가 포함된 문서 목록 뿐만아니라 단어의 관련성 혹은 유사성 (각 단어를 포함하는 문서의 수, 특정 문서에 단어가 나타나는 횟수, 각 문서의 단어 순서, 각 문서의 길이, 모든 문서의 평균 길이 등) 의 정보를을 저장할 수 있으며 이러한 통계를 통해 중요도 혹은 어떤 문서(document)가 중요한지 결정할 수 있다.
- 초기에는 하나의 거대한
Inverted Index가 전체 문서 모음을 위해 디스크에 쓰여진다. 새 색인이 준비되게 되면 이전 색인이 바뀌고 최근 변경사항을 검색 할 수 있게 된다.
1.1 Immutable (불변성)
- 디스크에 쓰여진 Inverted Index는 변경이 불가한 불변의(Immutable) 특성을 갖고 있다.
불변성의 이점
- 데이터 락을 걸 필요없이 일관성을 유지할 수 있다 : 동시에 변경을 시도하는 여러 프로세스에 대해 주의할 필요 없음
- 전체 Index가 버퍼 캐시에 로드 가능하다면, 변경이 없는 경우 항상 메모리에 로드된 상태이며 이는 File I/O 가 아닌 메모리 캐시를 통해 접근되므로 성능이 향상된다.
- Inverted Index를 작성하게 되면 데이터를 압축 할 수 있으므로 리소스 소모가 높은 디스크 I/O 를 줄이고 캐시하는데 필요한 RAM 의 용량을 줄일 수 있다.
불변성의 단점
- 말그대로 Update가 불가능하다.
- 새 문서를 검색 가능하게 하려면 전체 색인을 다시 작성해야 한다.
- 다시 작성해야 하기 때문에 인덱스에 포함 할 수 있는 데이터 양이나 업데이트 빈도에 상당한 제한이 있다.
어떻게 불변성의 이점을 잃지 않고 Inverted Index를 갱신할 수 있을까?
- 전체 Inverted Index를 재작성하는 대신 변화된 데이터를 나타내는 새로운 보조 인덱스를 추가한다.
- 검색 요청이 발생하면, 가장 오래된 인덱스부터 시작하여 결과를 조합하여 리턴한다.
2.Segment
shard는segment로 이루어진다.- document가 인덱싱될 때 데이터는 시스템 버퍼 캐시 영역으로 적재되며 이후 디스크의
segment에 기록하게 된다. - 이 과정에서 refresh를 거쳐야
commit point를 생성하며 검색 가능한 상태로 전환되게 된다.
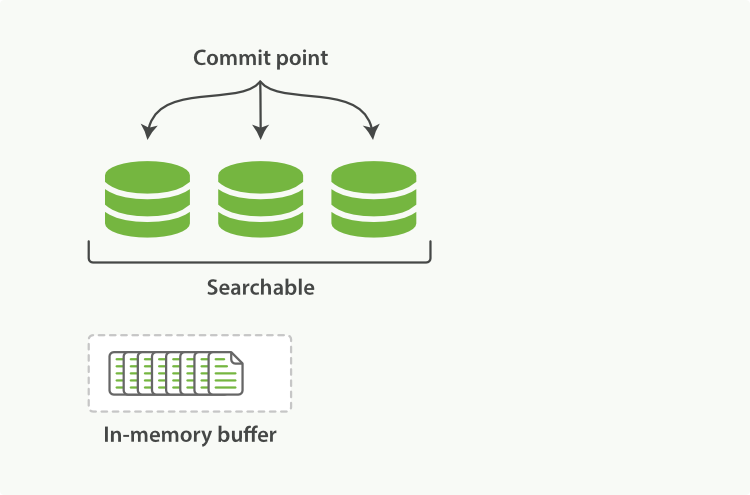
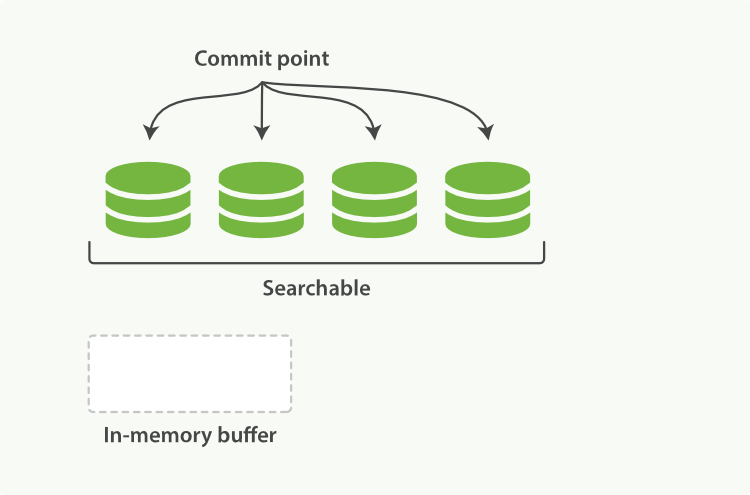
- Segment 는 하나의
Inverted Index를 의미하지만,commit point를 갖는 모든 추가된Inverted Index를 의미한다.