[Elasticsearch 검색 엔진 구축 강의] Elasticsearch 클러스터 분산구성 시나리오
Elasticsearch 검색 엔진 구축 강의

Contents
Elasticsearch 클러스터 분산구성 시나리오
1. 단일 노드에 3개의 샤드로 클러스터 구성하기
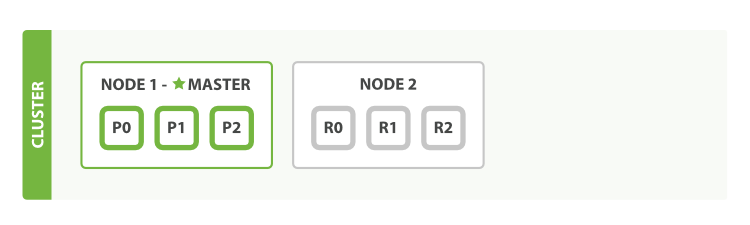
blogs라는 인덱스에 3개의 primary 샤드와 1개의 replica 샤드가 운용되도록 할당한다.
|
|

- 클러스터는 정상적으로 작동되나 하드웨어의 오류가 발생할 경우 데이터 손실의 위험이 있다.
- 데이터 적재량이 많을 경우 싱글노드가 허용하는 볼륨을 모두 소진할 수도 있어 더이상 적재가 불가능 할 수도 있다.
1.1 모든 기본 노드에 복제본 샤드 할당
- 클러스터에 동일한 설정의 노드를 한대 더 투입한다.
- 두 번째 노드가 클러스터에 추가되면 각 기본 샤드에 대해 하나씩 3개의
Replica shard가 생성된다. - 각 샤드에 대해
Replica shard가 존재하기 때문에 모든 데이터는 손상되지 않는다. - 새로 인덱싱 된 문서는 먼저 기본 샤드에 저장 된 다음 연결된 복제본 샤드에 병렬로 복제된다.
1.2 수평 확장
- 애플리케이션 수요 증가에 따라 노드를 확장해야 할 경우가 발생한다.
Node3을 시작하게 되면 2개의 샤드가Node3으로 이동되었으며, 각 하드웨어의 리소스(CPU, RAM, I/O)가 더 적은 수의 샤드에 공유되므로 각 샤드의 성능이 향상된다.
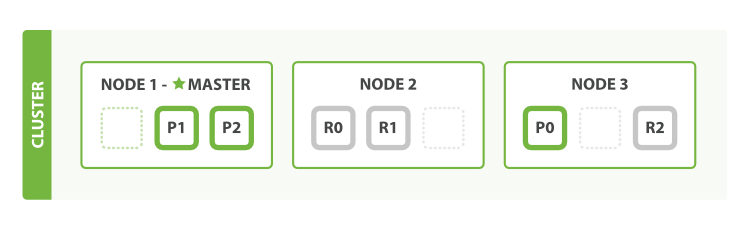
1.3 좀 더 확장하기
- 기본 샤드의 수는 인덱스 생성되는 순간 고정된다. 이 숫자는 인덱스에 저장할 수 있는 최대 데이터 양을 정의한다.
- 그러나 읽기 요청은 기본 샤드나 레플리카 샤드에서 처리할 수 있으므로 더 많은 레플리카가 있을 수록 더 많은 검색량 처리가 가능하다.
- 레플리카 개수는 동적으로 변경이 가능하다.
number_of_replicas를 1개에서 2개로 변경한다.
|
|
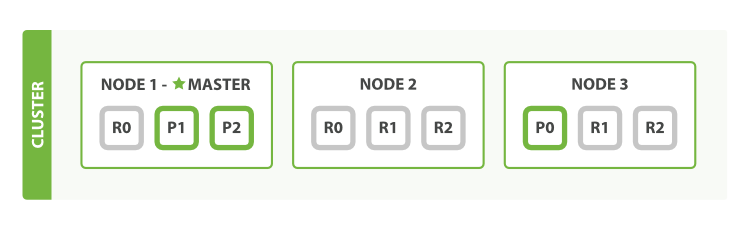
- 총 9개의 노드로 구성되어 있으며 3개의
primary shard와 6개의replica shard가 존재하게 되었다. - 위의 노드 구성을 통해 Node 2 개가 Fail 이 발생하여도 데이터의 손실은 막을 수 있다.
1.4 실패에 대처하기
1.4.1 한대의 노드가 fail 발생했을 경우
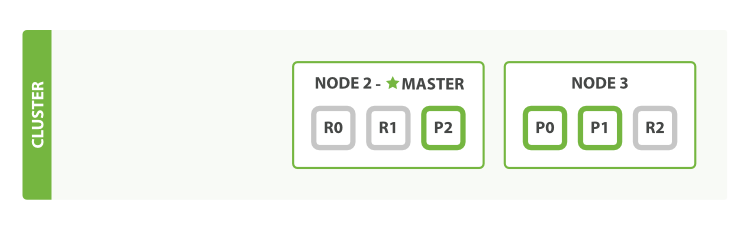
- 마스터 노드였던
Node 1번에Fail이 발생한다면 가장먼저 노드간 새로운 마스터 노드를 선출한다. - 남아있는 나머지 노드들의
replica shard가primary shard로 승격되게 된다.
Info
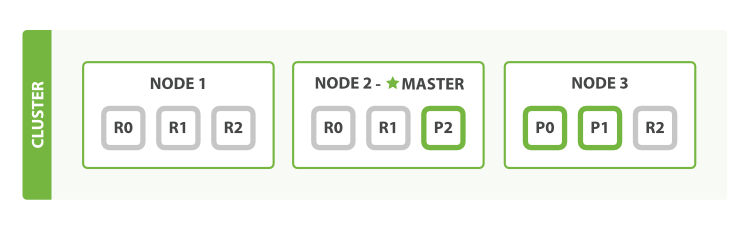
- 종료했던
Node1번을 다시 active 시키면 나머지 노드들이primary shard를 복제하여replica shard로 만든다.