[Elasticsearch 검색 엔진 구축 강의] Elasticsearch 시작하기
Elasticsearch 검색 엔진 구축 강의

Contents
🔍 Elasticsearch
- Apache Lucene 기반의 Full-Text 검색엔진이며 분석엔진
- 고가용성(High Availability)의 확장 가능한 오픈 소스
- HTTP 웹 인터페이스와 스키마에서 자유로운 JSON 문서로 제공
1. 검색 엔진으로서의 Elasticsearch
Elasticsearch 는 루씬 기반의 대중적인 엔터프라이즈 검색엔진으로 Apach 2.0 License 에 의거 오픈 소스로 출시 되었다. 또한 대부분의 루씬이 제공하는 기능들을 Eleasticsearch 에서도 제공한다. HTTP Web Interface와 Schema에 자유로운 JSON 형태의 도규먼트를 지원하는 준 실시간 분산형 검색엔진이다.
1.1 Apache Lucene
- 정보검색
Information Retrieval, IR소프트웨어 검색 라이브러리 - Apahce Software 재단의 검색엔진 상위 프로젝트
- 자바 언어로 개발되어 있다.
- 오픈소스
- 주요기능
- 사용자 위치 정보 이용 가능
- 다국어 검색 지원
- 자동 완성 지원
- 미리 보기 지원
- 철자 수정 기능 지원
2. 분석 엔진으로서의 Elasticsearch
Elasticsearch는 검색엔진으로 단독으로 서비스하지만 몇 가지 솔루션을 추가하여 분석엔진으로서도 활용이 가능하다.
2.1 관련 솔루션

Kibana
- Elasticsearch로 수집된 데이터를 통계 및 집계하여 시각화
Beats
- 데이터 수집기. 서버 혹은 단말에 Agent 형태로 로그나 데이터 원본을 Elasticsearch로 전달
Logstash
- 직접 로그를 전달하거나 Beats 에서 데이터를 전달받아 파싱 혹은 필터링 하여 Elasticsearch 로 전달
3. Elasticsearch의 용어 및 개념 정리
3.1 Document
- 도큐먼트는
JSON (Javascript Object Notation)형태의 Elasticsearch의 기본 저장단위이다. - 관계형 데이터 베이스의
Row와 비슷한 개념으로 볼 수 있다. - 도큐먼트는 데이터에 적재될 때
Document ID를 갖는다. - Document ID 는 지정하지 않으면 랜덤하게 생성되며, 사용자가 정의한 값으로도 생성 가능하다.
- Document ID 는 데이터를 찾아가는 Metadata 로 볼 수 있다.
3.2 Index
- Index 는 비슷한 형질을 가지는 도큐먼트 간의 집합이다.
- 관계형 데이터 베이스의
Database와 비슷한 개념으로 볼 수 있다. - 여러 도큐멘트들이 하나의 인덱스에 적재된다.
- 인덱스 이름은 문서에 대한 인덱싱/검색/갱신/삭제 등을 수행할 때 참조값으로 사용된다.
- 인덱스는 사전에 정의되어야 할 데이터 타입이나 특정한 구조가 필요하지 않다면 최초 데이터가 인입될 때 생성 된다. (고객정보, 제품카탈로그, 주문정보 등…)
3.3 Type
- 관계형 데이터베이스의
Table과 비슷한 개념으로 볼 수 있다. - 타입은 인덱스의 파티션으로 사용된다.
- 하나의 인덱스에 도큐먼트를 저장할때 타입을 분리해서 인덱싱이 가능하다.
Note
ES 6.0.0 버전 부터는 Multi Type 을 지정이
deprecated 되었으며, 하나의 인덱스에는 단일 타입으로만 지정하도록 권고하고 있다.3.4 Cluster
- Elasticsearch는 클러스터로 구성되어 있다.
- 클러스터는 전체 데이터 (모든 노드) 간 통합 인덱싱 및 검색이 가능한 1개 이상의 노드(서버)의 집합이다.
- 사용자는 이 클러스터를 통해 데이터를 저장하고 검색 요청을 할 수 있다.
- 클러스터는 고유의
cluster_name과cluster_uuid를 갖는다. - 클러스터 이름은 따로 지정하지 않으면 유니크한 이름으로 생성된다.
3.5 Node
- 노드는 클러스터를 구성하는 단일 서버로써, 서로 헬스 체크를 하거나 실제 데이터를 저장하고 클러스터에 참여하여 인덱싱과 검색 역할을 수행한다.
- 노드는 각자의 노드 이름을 갖으며 노드가 기동될때 랜덤 UUID 를 갖는다.
- 노드는 역할에 따라
master node,data node,all node,client node등으로 구성할 수 있다.
Note
모든 노드는 클러스터의 다른 모든 노드에 대해 알고 있으며, 클라이언트 요청을 해당 노드로 전달할 수 있다.
3.5.1 Node의 종류
| Node | Description |
|---|---|
| master node | 클러스터를 제어하는 마스터 노드. 구성 노드들의 헬스 체크를 담당한다 |
| data node | 데이터를 저장하고 검색 및 집계와 같은 데이터 관련 작업을 수행한다 |
| all node | master 혹은 data 노드의 구분이 필요 없을 때 두가지 역할을 담당한다. 보통은 확장이 필요 없거나 요청 쿼리가 많지 않고 데이터를 오래 보관해야 하는 경우 구성한다 |
| client node | 쿼리만을 받기 위한 노드이며, 부하가 많거나 요청 쿼리량이 많을 때 부하 분산용으로 구성한다 |
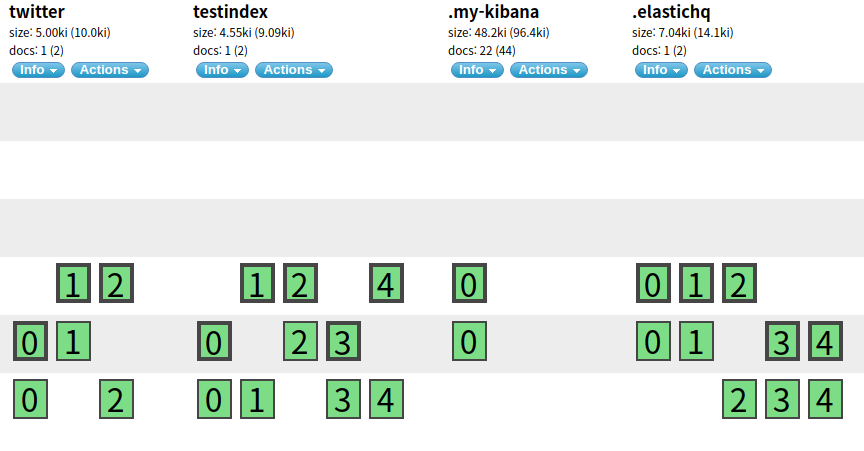
3.6 Shard
shard는 인덱스 데이터를 나누는 단위 이다.
인덱스는 무한한 데이터 저장이 가능하며
- 인덱스 데이터가 단일 노드의 하드웨어 용량을 초과하여 더이상 데이터를 저장할 수 없게 되거나
- CPU, 메모리 자원 초과로 인덱싱이나 검색 성능의 저하가 발생하는 문제가 발생
이와 같은 문제를 해결하기위해 ES에 도입된 개념이다.
3.6.1 샤딩의 특징
- 콘텐츠 볼륨의 수평(Horizontal) 분할 및 확장이 가능하다. 관계형 데이터베이스처럼 컬럼별로 나누는 것이 아닌 횡별로 나누어 샤드에 저장.
- 여러 샤드에 분산 배치하여 병렬화 함으로써 성능 및 처리량을 늘릴 수 있다.
- I/O 가 두배로 발생하여 인덱싱 성능이 저하된다.
- 디스크 볼륨 또한 실제 도큐먼트 용량의 두배가 필요하다.
3.6.2 Shard 의 종류
Primary Shard
Primary Shard는 인덱싱되어 들어온 Document의 원본 Shard를 의미한다.- Primary Shard는 각 인덱스 별로 최소 1개 이상 존재 해야한다.
- ElasticSearch에 Document가 인덱싱 될 때 가장 처음에 생성되는 샤드이다.
- 샤드 개수를 지정하지 않는다면 기본으로
5 개로 지정된다.
Replica Shard
Network / Cloud 환경의 샤드 노드가 오프라인 상태가 되거나 혹은 사라지게 될 경우를 대비하여 인덱스 샤드에 대해 하나 이상의 복사본을 생성할 수 있다. 이를 Replica Shard 라고 한다.
- ElasticSearch에서 Primary Shard가 인덱싱 된 후, Primary Shard가 저장된 데이터 노드와는 다른 곳에 복제된다.
- Replica Shard에도 넘버링을 하며, 어떤 Primary Shard의 복제본인지 식별이 가능하다.
- replica의
기본값은 1이다. - 인덱싱 시 Primary Shard의 복제하는 과정이 추가된다.
Info
- Elasticsearch의 샤드는 Lucene 의 인덱스이며, 단일 Lucene 인덱스가 포함할 수 있는 도큐먼트의 최대 개수는 2,147,483,519 개 이다
- Replica Shard 가 있기 때문에 샤드 혹은 노드의 오류가 발생하더라도 Elasticsearch 클러스터의 고가용성이 유지된다.
- 모든 Replica Shard에서 병렬 방식으로 검색을 실행할 수 있으므로 검색 처리량 확장 가능하다.